Wikipedia's bot traffic to overtake its human readers as costs surge
Summary
We pulled 82 months of data from Wikimedia's public pageview API. Human pageviews peaked at 19.9B/month in April 2020 and have fallen to 12.7B, a 36% decline. Annual bot traffic grew 87% over the same period, with monthly peaks hitting 13.1B. In December 2025, bots accounted for 49% of all Wikipedia pageviews.
Bot share crossed 40% in October 2023, right as AI search products scaled. Wikimedia Foundation infrastructure costs rose $18M in two years to $93M, now consuming half their budget, while human traffic keeps falling.
This matters for SEO because Wikipedia and Wikidata feed AI answers and Google's Knowledge Graph. As the human editorial workforce that maintains this content shrinks alongside traffic, the quality of the source material AI systems depend on is at risk.
The data
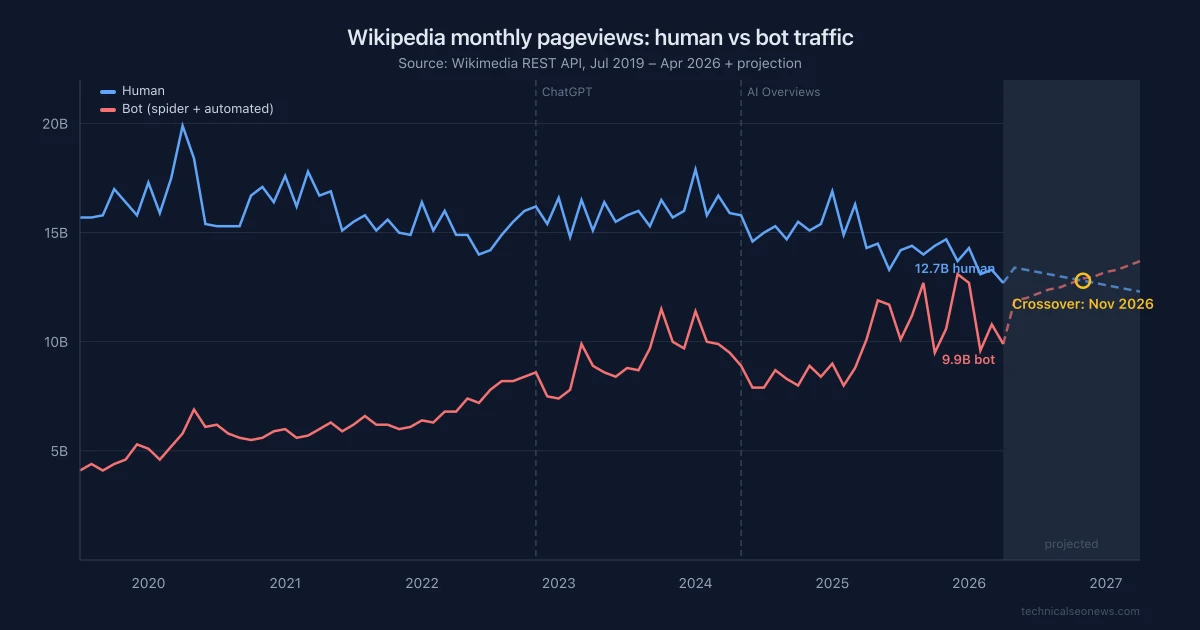
Wikipedia’s human traffic has fallen 36% from its 2020 peak. Bot traffic tripled over the same period. In December 2025, bots accounted for 49% of all Wikipedia pageviews. If current trends hold, the lines cross by late 2026.
We pulled 82 months of pageview data from Wikimedia’s public REST API, breaking traffic into human users, spiders (search engine crawlers), and automated bots. The chart above shows the trend with a linear projection (dashed lines) based on the last 24 months.
Human pageviews peaked at 19.9 billion in April 2020, during COVID lockdowns, and have been declining since. As of April 2026, human pageviews are at 12.7 billion per month, a 36% drop from peak.
Bot traffic moved in the opposite direction. On an annual basis, total bot pageviews grew from 68 billion in 2020 to 127 billion in 2025 (87% increase). Monthly peaks are more dramatic: bot traffic hit 13.1 billion in December 2025, up from 4.1 billion in mid-2019 when the dataset begins. That December, bots accounted for 49% of all pageviews. If current trends hold, the lines cross around November 2026 at roughly 12.8 billion each, though this is a simple linear projection and seasonal variation could shift the date in either direction.
The inflection points align with AI product launches. Bot share crossed 30% in mid-2022, around the time large-scale training runs intensified. It crossed 40% in October 2023, 11 months after ChatGPT launched.
| Year | Human (B) | Bot (B) | Bot share |
|---|---|---|---|
| 2020* | 200 | 68 | 25% |
| 2021 | 192 | 73 | 28% |
| 2022 | 183 | 90 | 33% |
| 2023 | 190 | 109 | 37% |
| 2024 | 188 | 108 | 36% |
| 2025 | 176 | 127 | 42% |
| 2026 (Q1) | 53 | 43 | 45% |
* 2020 bot figure undercounts: the “automated” subcategory only began tracking in April 2020. Jan-Mar 2020 includes spider traffic only.
Why this matters for SEO
Wikipedia sits upstream of almost every AI answer about entities. Google’s AI Overviews, ChatGPT, and Perplexity all draw on Wikipedia articles for factual grounding. Separately, Wikidata (Wikipedia’s structured knowledge base) feeds Google’s Knowledge Graph, which powers Knowledge Panels, voice assistant answers, and entity disambiguation. Between the two, Wikipedia and Wikidata are where AI systems go to figure out what an entity is and what is true about it.
That makes this traffic shift a signal-quality problem, not just a Wikipedia problem. The content AI systems depend on is maintained by volunteer editors. Those editors come from readers. 84% of Wikipedia’s human traffic comes from organic search, which means the volunteer pipeline is tied to Google referrals. As AI Overviews absorb clicks that used to go to Wikipedia, the editorial workforce that keeps Wikipedia accurate shrinks. AI systems keep consuming the content as if its quality is constant. It is not.
This is already showing up as a content integrity problem. AI answers strip Wikipedia’s dispute tags, citation-needed markers, and neutrality banners, surfacing contested claims as authoritative facts. Fewer editors means fewer people maintaining those quality signals in the first place.
Wikimedia acknowledged the infrastructure side directly: “Our content is free, our infrastructure is not.” Their infrastructure costs rose from $75 million in FY 2022-23 to $93 million in FY 2024-25, now consuming half their total budget. Even at lower bot-share estimates (Wikimedia’s own reporting puts it around 35%, lower than the API-derived 42% in our table, likely due to different classification methods), bots generate 65% of the most expensive traffic because they pull from origin data centers rather than edge caches.
Wikipedia’s response
Unlike most publishers, Wikipedia has not blocked AI crawlers in robots.txt. Their strategy is commercial: Wikimedia Enterprise, a paid API product launched in 2021, brought in $8.3 million in FY 2024-25 (up 148% year over year). Amazon, Meta, Microsoft, Perplexity, and Mistral AI signed on as paying customers in January 2026.
On the content side, Wikipedia banned LLM-generated article content in March 2026 by a 40-2 editor vote, allowing AI only for basic copyediting and translation. Their editors developed their own AI detection signals, dismissing automated detectors as “basically useless”.
The combination is unusual: open robots.txt, paid API for AI companies, banned AI-generated content within Wikipedia itself, and a volunteer base that is shrinking with the traffic. Whether it is sustainable is an open question. Enterprise revenue covers less than 10% of infrastructure costs, and that gap is not closing fast.
What practitioners should watch
Wikipedia is a degrading signal source. If your entity’s representation in AI answers depends on Wikipedia (and most entities’ representations do), the underlying content is being maintained by a shrinking workforce. Pages that were actively curated in 2020 may be stagnating now. For any entity you manage, check the Wikipedia page’s edit history: compare edit frequency over the last 12 months to 2020-2022, look for unresolved dispute tags or citation-needed markers, and check whether the talk page still has active participants. A page on a settled topic (a historical figure, a scientific concept) can go months without edits and be fine. But a page about an active company or product that used to get regular updates and has gone quiet is a different signal.
Check your Wikidata entry. Wikidata is CC0-licensed (fully public domain) and feeds Google’s Knowledge Graph with structured entity data. While you cannot guarantee how Google weighs it against other sources, keeping your entity’s Wikidata entry accurate and current is lower-friction than editing Wikipedia and less subject to editorial disputes. Note that schema markup alone does not directly influence how LLMs parse your entity, but consistent structured data across your own properties and Wikidata gives AI systems multiple sources to cross-reference.
Monitor for policy shifts. Wikipedia keeping robots.txt open while infrastructure costs climb is not a stable equilibrium. If Enterprise revenue doesn’t close the gap with infrastructure costs, crawl controls could change. Any restriction on AI crawlers’ access to Wikipedia would have cascading effects on AI answer quality for every entity that depends on Wikipedia-sourced information.
Methodology
Data was pulled from the Wikimedia REST API pageviews endpoint on May 13, 2026. We queried all-projects (all Wikimedia properties including all language Wikipedias) with all-access (desktop + mobile web + mobile app), at monthly granularity, from July 2019 through April 2026. Agent types queried separately: user (human), spider (search engine crawlers), and automated (other bots). “Bot” in this analysis combines spider + automated.
The November 2026 crossover estimate uses ordinary least squares linear regression on the most recent 24 months of data for each series (human and bot). The intersection of the two trend lines gives the projected date. This is a naive projection, not a forecast. Wikipedia pageview data has seasonal variation (lower in summer, higher in autumn/winter), and any policy change by Wikimedia (such as throttling bot access) or a shift in AI crawling patterns would invalidate the trend. The projection assumes current conditions continue unchanged, which is unlikely over a 12-month horizon. We include it to illustrate the trajectory, not to predict a specific date.
Caveats: Wikimedia reclassified some mid-2025 traffic from human to bot after discovering that bots from Brazil were masquerading as human visitors. The automated agent category started tracking in April 2020, so pre-2020 bot figures undercount. Infrastructure cost figures come from Wikimedia Foundation annual reports (fiscal years ending June 30) and are not directly comparable to calendar-year pageview data.