Latest Technical SEO News
Crawling changes, algorithm updates, rendering fixes, and structured data developments as they happen.
-
Screaming Frog 24.0 adds MCP server and uncrawlable link detection
SEO Spider 24.0 lets AI assistants run crawls via MCP, flags non-standard link markup, and auto-compares scheduled crawls with emailed deltas.
-
Agentic search drops sites lacking extractable claims
Google's agentic search filters businesses out of results when pages lack specific pricing, service areas, or hours. Rankings alone no longer guarantee visibility.
-
ChatGPT free and paid users see two different webs
GPT-5.3 and GPT-5.4 share only 7% of cited sources on identical prompts. Five independent studies reveal how subscription tier reshapes source selection.
-
AI search cites size guides and support pages over product pages
Analysis of 25 ecommerce sites finds AI systems cite fit guides, return policies, and tutorials far more than PDPs or PLPs when resolving buyer queries.
-
Silent soft 404s caused 90% traffic loss after site migration
Pages returned HTTP 200 but Google's quality classifiers flagged them as soft 404s, deindexing thousands of URLs before the traffic drop was visible.
-
1,800 pages deindexed overnight despite clean GSC signals
A WordPress site lost all indexed pages while GSC showed no errors. The blank canonicals looked technical, but the community and Google's own docs point to quality.
-
Managing AI bot traffic with robots.txt and beyond (and why)
Spoofed AI bots ignore robots.txt while legitimate ones comply. Practitioners need forward-confirmed reverse DNS and CDN rate limiting, not just directives.
-
AI Overviews show negative reviews in unrelated queries
Brand complaints now show in AI Overview comparisons without reputation intent. Google and ChatGPT go negative for different reasons, and disagree on which brand to flag 73% of the time.
-
Ahrefs study finds JSON-LD schema does not boost AI citations
Ahrefs tracked 1,885 pages adding JSON-LD schema across AI Overviews, AI Mode, and ChatGPT. No citation uplift on any platform. AI Overviews declined 4.6%.
-
Google's Glue system re-ranks results using SERP behavior you can't see
SALT.agency claims Google's Glue system tracks hovers, scrolls, and dwell time on SERP features to re-rank results. What practitioners should know.
-
Empty category pages trigger soft 404s with no clean fix
Google flags out-of-stock category pages as soft 404s, but removing them risks slow re-indexing when products return. Each option has real tradeoffs.
-
Figma Sites migration yields 39-second LCP, stalled indexing
A Webflow-to-Figma Sites migration produced 2,000 new 404s and 30 crawled-but-not-indexed pages. Client-side rendering delays block Googlebot entirely.
-
Lighthouse 13.3 adds agentic browsing audits for AI agents
Lighthouse 13.3 ships four new checks including accessibility tree well-formedness, WebMCP validation, llms.txt compliance, and CLS for AI agent contexts.
-
Why IA migrations break without a staging crawl
Redirect mapping misses consolidation relevance gaps, platform canonical conflicts, and orphaned navigation paths. A staging crawl catches these before Googlebot does.
-
Agent runtimes, not models, now control how AI reads your site
Cloudflare and OpenAI shipped agent runtime SDKs that fetch and parse your pages before any model sees them, breaking sites that depend on client-side JS.
-
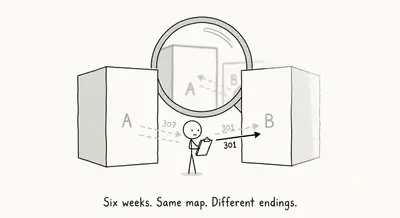
Six weeks of 307 redirects split two identical migrations
Two identical subdomain migrations diverged because six weeks of 307 temporary redirects delayed canonical signals, and a sitemap parsing error compounded one.
-
Google officially deprecates FAQ rich results as of May 2026
Google is phasing out FAQ rich results starting May 7, 2026. Teams using Search Console API integrations need to update before August cutoff.
-
Next.js patches 13 vulnerabilities in security release
Next.js patched 13 vulnerabilities in versions 15.5.18 and 16.2.6. Middleware bypasses can expose protected content to crawlers without auth checks.
-
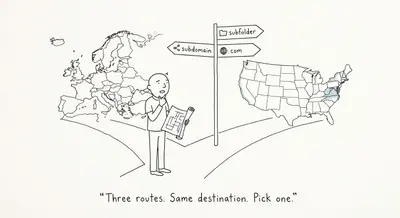
Subfolder, subdomain, or separate .com? A composable-stack call
An EU retailer choosing between subfolder, subdomain, and separate domain for a US store faces composable-stack routing that makes hreflang invisible to Google.
-
Google's quality sampling kills scaled content, not AI detection
Google's quality sampling of new URLs causes scaled content collapse, not AI detection. Poor sample performance triggers crawl reduction across the entire batch.