LLMs misrepresent brands at training, retrieval, and generation
Summary
LLMs distort brands at three points: training data ingestion, document retrieval at query time, and response generation. Each stage compounds the problem independently.
Brand visibility work has focused only on fixing outputs, but the real issue is structural across the pipeline. Retrieval-augmented generation surfaces stale or third-party content that feeds directly into generated answers.
Audit your brand mentions in ChatGPT and Gemini, strengthen Schema.org markup on your site, and clean up inaccurate references on high-authority pages that RAG systems retrieve.
What happened
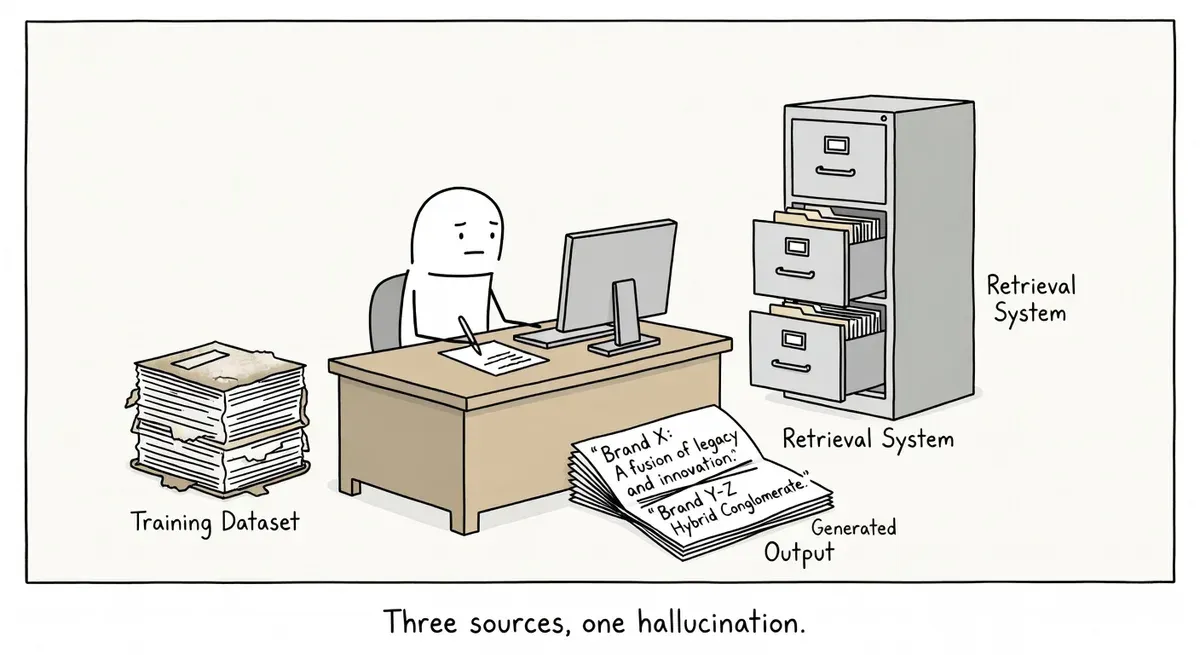
A Search Engine Land analysis published April 30 breaks down how large language models can misrepresent brands at three distinct stages: when training data is ingested, when documents are retrieved at query time, and when the model generates its final response. The piece argues that brand distortion is not a single-point failure but a compounding problem across the full LLM pipeline.
The three failure points map roughly to how modern AI search systems work. Training data shapes the model’s baseline “understanding” of a brand. Retrieval-augmented generation (RAG) pulls in fresher documents at query time but may surface outdated or off-brand content. The generation step then synthesizes all of that into a response, introducing further risk of hallucination or conflation with competitors.
Why it matters
Most brand-visibility work in AI search has focused on the output layer: checking what ChatGPT or Gemini says about a brand and trying to correct it. The Search Engine Land analysis reframes the problem as structural. If training data already contains outdated messaging, fixing the generation layer alone will not solve the issue.
Training data is largely static. Models ingest web content at a point in time, and that snapshot may include old product descriptions, discontinued services, or third-party content that mischaracterizes the brand. Practitioners have limited control over what gets included.
The retrieval layer is where SEOs have more leverage. RAG systems pull from live or semi-live indexes. The content that ranks well in traditional search or appears in knowledge bases is likely to be retrieved. Poorly structured or ambiguous content at this stage feeds directly into the generated answer.
Generation-stage distortion is the hardest to control. Even with accurate training data and clean retrieval, models can blend information from multiple entities or hallucinate details. A brand with a generic name or one that shares terminology with competitors is especially vulnerable.
What to do
Audit your entity footprint across the web. Search for your brand in major LLM-powered tools (ChatGPT, Gemini, Perplexity) and document where the response diverges from your actual positioning. Note whether errors look like stale training data or retrieval-stage problems.
Strengthen structured data on your own properties. Use Schema.org Organization markup to define your brand’s name, description, founding date, logos, and key attributes. Structured data gives retrieval systems unambiguous signals about your entity. Include sameAs properties pointing to your Wikipedia page, LinkedIn, and other authoritative profiles.
Clean up third-party references. Identify high-authority pages that describe your brand inaccurately. These are likely retrieval candidates for RAG systems. Request corrections on Wikipedia, industry directories, and partner sites. Outdated press releases and old product pages on your own domain are also retrieval risks.
Consolidate brand messaging into a clear, crawlable “about” page. A single authoritative page with your current positioning, product lines, and differentiators gives both training crawlers and RAG systems a definitive source. Avoid splitting brand-defining content across dozens of pages with inconsistent language.
Monitor regularly. LLM outputs change as models are retrained and retrieval indexes refresh. Set a recurring check, monthly at minimum, to query your brand across AI tools and compare results against your current messaging.
Watch out for
Brand-name ambiguity multiplies risk. If your brand name is also a common word or overlaps with another company, LLMs are more likely to conflate entities at every stage. Structured data and consistent use of your full legal name help, but this is an ongoing problem without a clean fix.
Old content on your own domain can work against you. Archived blog posts, deprecated product pages, and outdated case studies are all fair game for training and retrieval. If you cannot remove them, add clear date signals and consider noindexing content that no longer reflects your brand.