Managing AI bot traffic with robots.txt and beyond (and why)
Summary
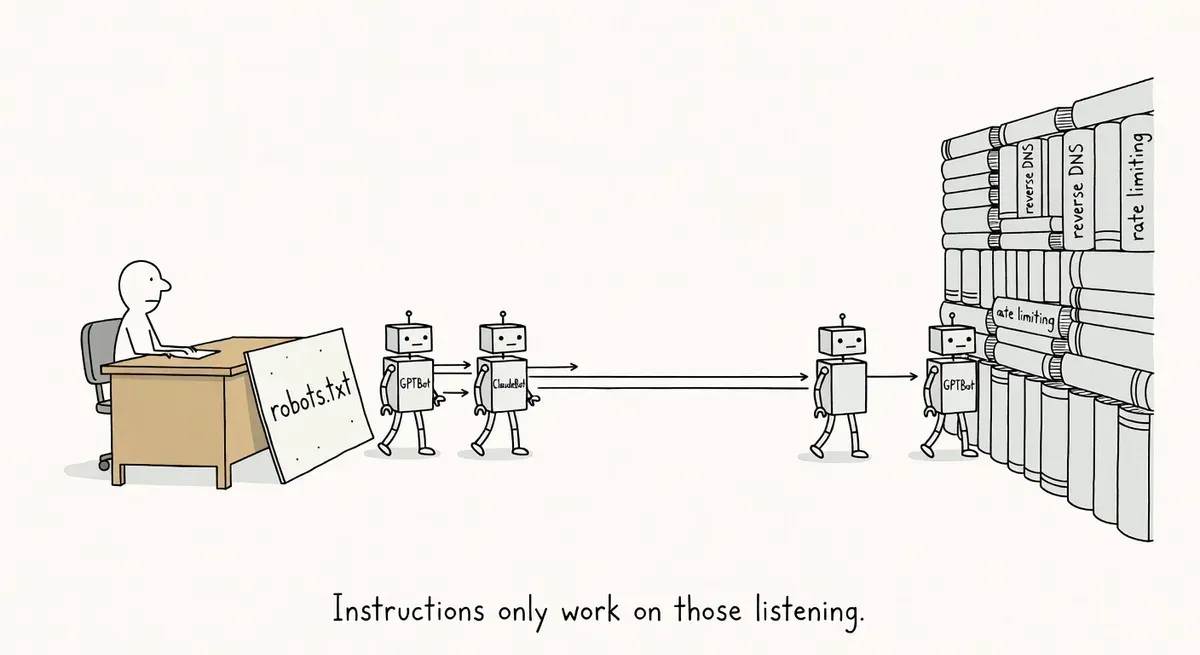
Most AI crawlers from known vendors respect robots.txt, but spoofed user agents and unrecognized bots ignore it entirely. Robots.txt rules are requests, not enforcement mechanisms.
Forward-confirmed reverse DNS and CDN-level rate limiting are the actual controls. Training crawlers, retrieval bots, and user-action fetchers each warrant different blocking policies.
The crawl-budget concern is real but misunderstood: AI bots don't consume a shared quota, but server strain from aggressive crawling can cause Googlebot to reduce its own crawl rate.
What happened
A discussion in r/TechSEO surfaced a common frustration: AI crawlers are hammering sites, ignoring crawl-delay directives, and targeting low-value parameter-heavy URLs hundreds of times per day. The original poster reported seeing bots from ChatGPT, Claude, and various Googlebot-like user agents that don’t resolve properly via reverse DNS.
The thread captures a real split among practitioners. Some block all AI bots outright. Others allow specific ones like GPTBot while blocking the rest. A few take a wait-and-see approach, worried about losing future visibility in AI-powered search results.
One commenter noted they allow only known, well-documented bots and rate-limit everything else.
The core tension is clear: blocking feels like closing a door on potential AI search visibility, but allowing everything means absorbing bandwidth costs from bots that may offer zero return. Some managed WordPress hosts already block AI crawlers by default without telling site owners, adding a layer of invisible decision-making.
Why it matters
The conversation exposes a problem that robots.txt alone cannot solve. RFC 9309, the robots exclusion protocol spec, clarifies user-agent matching rules but does not establish any access-control mechanism. Crawlers are requested, not technically required, to honor these directives. A Disallow rule only works when the crawler chooses to honor it.
Legitimate AI crawlers from major vendors do claim to respect robots.txt. OpenAI’s GPTBot documentation states that disallowing GPTBot signals that content should not be used for training, and IP ranges are published for verification. Anthropic states that ClaudeBot respects robots.txt directives.
But the thread highlights a different problem: spoofed user agents claiming to be these bots, or unrecognized crawlers with no published compliance policy at all.
Mid-size sites feel this most acutely. A site with 100K+ pages and historical parameter variants (color/size combos, old filters) faces real exposure. A large share of daily crawl requests can come from unrecognized bots targeting outdated URLs. Each request may trigger a database query despite returning a canonicalized or redirected page.
The bandwidth and compute cost is measurable. Cloudflare reported AI crawlers generating over 50 billion requests per day across its network, and CEO Matthew Prince has said bot traffic will exceed human traffic by 2027.
The Wikimedia Foundation found that AI bots represented 35% of total pageviews but accounted for 65% of their most expensive requests, a pattern we analyzed in depth using 82 months of Wikimedia API data. A Sitebulb analysis found OpenAI bots alone crawled a site 12x more frequently than Googlebot. For sites on metered hosting, this translates directly to higher bills.
The crawl budget concern matters too, but is often misunderstood. Crawl budget is not a fixed quota that competing bots consume. Google’s robots.txt documentation defines how Googlebot handles directives, but Google Search Console doesn’t account for non-search bots competing for server resources.
If non-Google bots degrade server response times, Googlebot may reduce its own crawl rate. The server capacity component of crawl budget is what’s at risk, not a shared pool.
The strategic question is also unresolved. As of May 2026, no public documentation from Google or Bing confirms whether training data provenance affects ranking or citation in AI-powered search features.
What is clear is that AI-referred traffic has real value. Adobe’s Q1 2026 data shows AI-referred visits convert 42% better than non-AI traffic, concentrated on pages AI crawlers can actually parse. That makes the blocking decision harder: the infrastructure costs are real, but so is the traffic you lose by blocking retrieval bots.
What to do
Start with log analysis, not robots.txt changes. Identify which AI user agents are actually hitting your site, how often, and which URLs they target. Look for patterns: bots hammering parameter-heavy pages, archived content, or faceted navigation URLs are a sign of wasted resources. Treat bot monitoring as an ongoing operational metric, not a one-time audit.
Validate bot identity before trusting user-agent strings. The methods depend on the bot. For Googlebot, the documented approach is forward-confirmed reverse DNS (FCrDNS): reverse-lookup the IP to get the hostname, confirm the hostname ends in .googlebot.com or .google.com, then forward-lookup that hostname to confirm it resolves back to the original IP.
For OpenAI’s bots, the documented method is IP range validation. OpenAI publishes IP ranges for GPTBot at openai.com/gptbot.json. If a bot claims to be GPTBot but its IP isn’t in that range, it’s a spoofer. Block it at the server or CDN level, not in robots.txt.
Google is also developing Web Bot Auth, a cryptographic protocol that would replace spoofable user-agent headers with signed HTTP requests.
For bots you can verify as legitimate, make a deliberate per-bot decision:
- Training crawlers (GPTBot, ClaudeBot) scrape content for model training. Blocking them prevents your content from being used as training data and has no known impact on current search rankings or real-time retrieval (handled by separate bots like OAI-SearchBot). Training data is generally understood to influence future model behavior, so the long-term visibility implications remain genuinely unknown.
- Search/retrieval bots (OAI-SearchBot, PerplexityBot) power AI search answers. Per OpenAI’s documentation, sites that opt out of OAI-SearchBot will not be shown in ChatGPT search answers. Blocking retrieval bots reduces the likelihood of your content appearing in AI search products over time. For context on how OAI-SearchBot activity has surged since GPT-5, see our earlier coverage.
- User-action fetchers (ChatGPT-User) make real-time requests when a user asks the AI to fetch a URL. Per OpenAI’s documentation, because these actions are user-initiated, robots.txt directives may not be honored. Server-level controls are more appropriate here.
- Autonomous AI agents (Operator, Claude computer use, agentic browsing tools) browse interactively through headless browsers, clicking links, filling forms, and completing multi-step tasks. They don’t use standard bot user-agents and often appear as regular Chrome traffic. Robots.txt and FCrDNS are both ineffective here. Google is already telling developers to build for these agents, but almost no sites are ready (Cloudflare data shows under 4% of top sites support agent-specific directives). This is a different access pattern from crawling and requires different controls like authentication and behavioral detection.
Implement rate limiting at the CDN or application layer for unverified and unwanted bots rather than relying on Crawl-delay in robots.txt. Never rate limit Googlebot or Bingbot. If your server slows down from bot load, Googlebot already reduces its own crawl rate automatically. Artificially throttling it further risks losing crawl coverage on large sites.
The Crawl-delay directive in robots.txt is not part of the RFC 9309 standard. Bing and Yandex honor it, but Google ignores it. Google used to offer a crawl rate limiter in Search Console, but removed it in January 2024. Googlebot now adjusts its crawl rate automatically based on server response times and HTTP 500 errors.
None of these mechanisms apply to AI crawlers. Cloudflare, Fastly, and other CDNs offer bot-specific rate limiting that enforces request caps per user-agent or IP range. If you’re on shared hosting without CDN access, Cloudflare’s free plan includes basic bot management, or use server-level rules (.htaccess on Apache, nginx.conf rate limiting) as a fallback.
If you decide to block specific AI crawlers in robots.txt, be precise with user-agent matching. Use the exact token each bot documents (e.g. GPTBot, ClaudeBot, PerplexityBot). Per RFC 9309, user-agent matching is case-insensitive and based on the product token the crawler declares, not arbitrary substring matching within the full HTTP User-Agent header.
A robots.txt Disallow will block the real GPTBot but cannot distinguish it from a spoofed agent claiming the same token. Server- and CDN-level IP validation is necessary alongside robots.txt rules.
Watch out for
Spoofed user agents bypass robots.txt entirely. A Disallow rule for GPTBot stops the real GPTBot but does nothing against a scraper using the same user-agent string. You need server-level IP validation to catch these.
Granular bot policies create maintenance debt. Allowing GPTBot but blocking ClaudeBot based on today’s assumptions about which AI search product will matter most locks you into a bet. If the landscape shifts, you’ll need to rewrite policies. Document your decisions and review them quarterly.
Broad User-agent: * rules can block bots you didn’t intend to block. If your robots.txt has a specific section for Googlebot and Bingbot, those bots will follow their own section and ignore User-agent: *. But any bot without its own named section falls back to the * rules. That includes lesser-known legitimate crawlers, monitoring tools, and new search engines you haven’t added yet. If you want to block AI crawlers specifically, name them individually (GPTBot, ClaudeBot, PerplexityBot) rather than tightening the wildcard.