Latest Technical SEO News - Page 2
Crawling changes, algorithm updates, rendering fixes, and structured data developments as they happen.
-
Google AI Mode adds five link types that complicate attribution
Google added five new link types to AI Overviews including inline links and discussion previews. Attribution now works differently than traditional search results.
-
Google tests Gemini 3 model selector in the search bar
Google is testing Pro, Fast, and Auto model selectors for Gemini 3 in the search bar, which could fragment AI Overview citation tracking across model variants.
-
Managed WordPress hosts silently block AI crawlers
Managed WordPress hosts block AI crawlers by default, preventing your content from appearing in ChatGPT search and Perplexity results. Check robots.txt now.
-
Schema markup does not influence LLM parsing
Schema markup does not help LLMs parse content because transformer models read token sequences, not markup. Vendors are misrepresenting how AI engines actually work.
-
URL paths are semantic inputs for RAG pipelines, not just SEO
URL path segments now function as semantic inputs for RAG systems and LLMs, not just SEO signals. Descriptive paths improve AI retrieval and citation accuracy.
-
Next.js streaming metadata fails Google indexing
Next.js streaming metadata gets indexed without titles and canonicals because Googlebot doesn't wait for dynamic tags to resolve in the body tag.
-
GSC reports resource failures despite 200 OK in server logs
A WooCommerce site logs clean 200 responses to Googlebot, but GSC flags resource failures caused by CDN interception or timing gaps between crawl and render.
-
Google's Web Bot Auth adds cryptographic bot identity
Google's Web Bot Auth adds cryptographic signing to HTTP requests, replacing spoofable user-agent headers with verified bot identity that works across IP ranges.
-
Google's query fan-out splits AI queries against classic search
Google breaks AI queries into sub-queries matched against classic search results. Your pages need to rank for decomposed fragments, not complex full questions.
-
Noindex vs. robots.txt disallow for millions of stub pages
Noindex and robots.txt disallow have different effects on crawling and indexing. Verify you have a crawl budget problem before blocking stub pages at scale.
-
ChatGPT free tier triggers web search in only 10.8% of queries
Free ChatGPT uses live web search in only 10.8% of queries versus 47.4% for paid, leaving users vulnerable to stale data and misinformation.
-
Google tells developers to build websites for AI agents
Google published a web.dev guide treating AI agents as a distinct audience, recommending semantic HTML and stable layouts that map to existing WCAG patterns.
-
Semrush launches AI agent readiness audits for technical SEO
Semrush Site Audit now scores AI agent readiness, but the real finding is that client-side rendered pages hide pricing and product data from agent runtimes.
-
B2B SaaS listicles and comparison pages losing rank weight
B2B SaaS companies report self-promotional listicles and competitor comparison pages losing search visibility, consistent with helpful content system signals.
-
LLMs misrepresent brands at training, retrieval, and generation
LLMs misrepresent brands across training, retrieval, and generation stages. Strengthen Schema.org markup and audit third-party references to improve entity accuracy.
-
WordPress to SvelteKit migration risks crawlability regression
SvelteKit migrations from WordPress require explicit SSR setup and manual schema markup to avoid losing crawlability. Test rendering before launch.
-
Migration traffic drops need pre-defined thresholds, not panic
Define traffic loss thresholds before migrating your site. Pre-set benchmarks for revenue and transactions prevent panic and unnecessary rollbacks during recovery.
-
Screaming Frog Log File Analyser 7.0 verifies AI bot identity
Screaming Frog Log File Analyser 7.0 now verifies AI bot identity using IP ranges and reverse DNS, so you can separate genuine crawlers from spoofed ones.
-
Declarative Shadow DOM cuts render-blocking JS
Declarative Shadow DOM removes render-blocking JavaScript by defining shadow roots in HTML instead, improving Web Components performance across all major browsers.
-
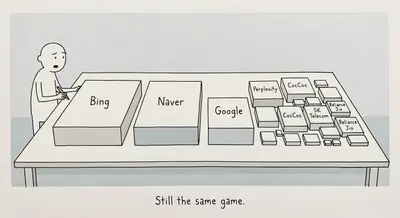
APAC search fragments across Bing, Naver, AI, and super-apps
Bing holds 32% share in Japan and Naver rivals Google in South Korea, while telecom-bundled AI tools reach hundreds of millions across the region.